Larry Hughes: ECED 2400 (Systems Analysis)
Department of Electrical and Computer Engineering
Dalhousie University
Dataflow Diagrams: Construction and Layering
Dr. Larry Hughes
Introduction
In Introduction to Dataflow Diagrams, the basic
features and functions of dataflow diagrams were introduced.
In this document, some suggestions as to how dataflow diagrams can be
constructed are discussed.
It is worth noting that there are no hard and fast rules
associated with dataflow diagrams (as with most things dealing with
computer software), just common sense.
Furthermore, it is worth remembering that different companies may use
variations on the dataflow diagrams shown here; if you find yourself in
this situation, remember to be be flexible.
Construction
Most practitioners of dataflow diagrams suggest that the following five
issues be considered when creating DFDs:
-
Choose meaningful names.
All entities (processes, flows, stores, and terminators), should have
'meaningful' names.
A meaningful name is one that refers to the task that the entity performs
(i.e., processes or terminators) or the data the entity supports (flows or
stores).
'Good' names are ones such as VALIDATE_STUDENT_ID and
CHECK_FLIGHT_TIME, rather than DO_IT or BILL'S_JOB.
-
Number all processes.
All processes are associated with a label.
In some cases, these labels can be quite long and might not 'rattle off the
tongue' that easily.
For this reason (and layering, discussed below), it is often easier to refer
to a process bubble by number rather than by name.
The 'downside' to using numbers rather than names is that it implies an
order of the bubbles.
In most instances, this will not be the case; the user/client should be
informed that the number scheme is to simplify the understanding of the
diagram, rather than implying an order.
-
Avoid complex dataflow diagrams.
Complex dataflow diagrams should be avoided; for example, the following
diagram would probably scare off most users (not a good thing):
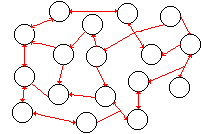
Instead, it is suggested that a DFD should not consist of more than 6
or so process bubbles on a sheet of paper.
Systems that require more than 6 process bubbles should be broken down
into layers (see below).
-
Redraw dataflow diagrams as often as necessary.
The first attempt at a DFD may not be what the user wants and upon
inspection, it might not be what you want.
As a result, be prepared to draw (and redraw) the DFD as many times as
necessary.
-
Make dataflow diagrams logically consistent.
When inspecting a dataflow diagram, watch for the following:
-
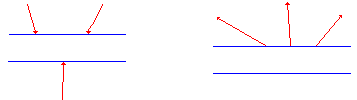
Avoid infinite sinks in which data flows into a process but there
are no output flows:

-
Avoid spontaneous generation bubbles, in which data flows from
a process with no inputs:
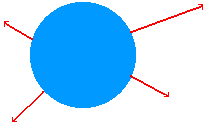
-
All entities in a DFD (i.e., processes, flows, stores, and terminators)
should be labelled.
-
Stores, like processes, should be written so that they have both input
and output flows.
Accordingly, correct any stores that are 'write-only' or 'read-only':
Layering Dataflow Diagrams
In addition to the issues that should be considered when creating a
dataflow diagram, there are several other techniques that can be
employed to simplify their interpretation.
Common sense suggests (as does one of the issues listed above), that
dataflow diagrams should not look like:
The approach used by designers using DFDs is to represent the system
as a series of layers, the topmost being the context diagram
of the system.
The context diagram is essentially the environment/system view;
however, in this case, the environment consists of the various terminators
that interact with the system:
Layering allows the problem to be partitioned into its various
components: processes, stores, and terminators.
These components can be linked together by the flows.
Once the context diagram has been completed, the first layer that
makes up the system can be represented.
This consists of the principal processes, stores, terminators, and
flows.
This layer is referred to as Figure 0:
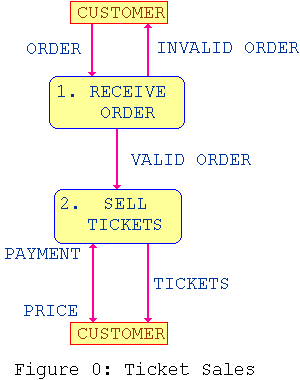
Each process in Figure 0 must be given a number and a name; each
process is then expanded into its own figure, using its process number from
Figure 0.
For example, Figure 2 would be written as:
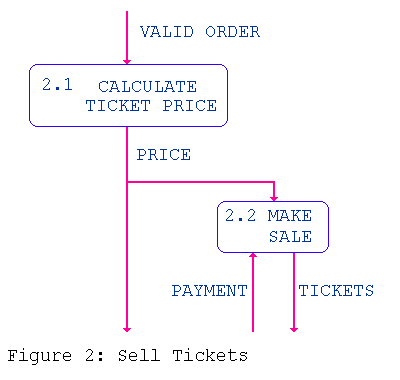
The following are some suggested guidelines for writing layered dataflow
diagrams:
-
Always attempt to create an equal number of layers.
That is, if Figure 1 eventually expands to Figure 1.1.1 (i.e., two layers below
Figure 0), all other layers should expand two layers below Figure 0.
If the layers are slightly unbalanced, this should not be an issue; however,
if there is a great discrepency in the number of layers, it probably means that
the DFD should be redesigned.
-
The number of flows into and out of, say, process 1 in Figure 0, should
correspond to the number of flows into and out of the processes in
Figure 1.
-
If a process connects to a store, that connection should be shown in all
subsequent layers of the process.
© 2005 -- Whale Lake Press